1년여간 이 분이 이러한 브랜칭 모델을 사용했고 그에 대한 이야기를 적어놓았던 글이 화제가 되어 현재 많은 개발자들이 이 모델을 많이 사용하고 있다.
Git-Flow에 대해 간략한게 설명해보자면 이 모델은 5가지 브랜치를 사용하는 모델이다.
Master(Main) - 제품으로 출시되는 Branch, Production의 개념을 내포하고 있다.
Develop - 다음 출시 버전을 개발하는 Branch
Feature - 기능을 개발하는 Branch, 주로 이 브랜치에서 개발을 한다.
Release - 이번 출시 버전을 준비하는 Branch, QA를 진행하는 브랜치이다.
Hotfix - 출시 버전에서 발생한 버그를 수정하는 Branch
Git-Flow를 사용해서 개발하는 순서는 보통 아래와 같이 이루어진다.
처음에 Master(Main)와 Develop 생성
새로운 추가 작업은 Develop에서 Feature Branch 생성
Feature는 Develop으로 Merge(이때 Develop이 최신 상태인지 확인해야함)
QA를 위해서 Develop에서 Release Branch 생성
QA에서 발생한 버그는 Release에서 수정
QA가 끝나면 Release에서 Develop / Master(Main)으로각각 Merge
Hotfix는 Master에서 시작하여 수정 후Master / Develop에 Merge
Git-Flow가 유용하긴 하지만 너무 많은 브랜치를 사용하는 점, 그에 따라 안쓰는 브랜치가 생기고 브랜치 마다 포지션이 애매해질 수 있기 때문에 이러한 점을 보완해 좀 더 간소화 된 브랜칭 전략이 나왔는데 그것이 GitHub-Flow이다.
GitHub-Flow란 Git-Flow가 복잡하기에 이를 좀 더 간소화시킨 방식으로 Scott chacon이 Github에서 좀 더 편리하게 사용하기 위해 만든 브랜칭 전략이다.
자동화 개념이 포함되어 있으며 Master(Main) Brnach에 대한 role만 정확하다면 나머지 Branch들에는 관여를 하지 않는다. 그리고 Pull Request 기능의 사용을 권장한다.
사용법 및 특징을 정리해보면
1. Master Branch의 어느것이든 배포가 가능하다.
master 브랜치는 항상 최신 상태며, stable 상태로 product에 배포되는 브랜치
이 브랜치에 대해서는 엄격한 role과 함께 사용한다
merge하기 전에 충분히 테스트를 해야한다. 테스트는 로컬에서 하는 것이 아니라 브랜치를 push 하고 Jenkins로 테스트 한다
2. 새로운 일을 시작하기 위해 Branch를 Master에서 딴다면 이름은 어떤 작업인지 명확하게 명시한다.
브랜치는 항상 master 브랜치에서 만든다
Git-flow와는 다르게 feature 브랜치나 develop 브랜치가 존재하지 않음
새로운 기능을 추가하거나, 버그를 해결하기 위한 브랜치 이름은 자세하게 어떤 일을 하고 있는지에 대해서 작성해주도록 하자
커밋메시지를 명확하게 작성하자
3. Local Branch에 수시로 커밋하고 이 내용을 원격 Branch에 수시로 Push한다.
Git-flow와 상반되는 방식
항상 원격지에 자신이 하고 있는 일들을 올려 다른 사람들도 확인할 수 있도록 해준다
이는 하드웨어에 문제가 발생해 작업하던 부분이 없어지더라도, 원격지에 있는 소스를 받아서 작업할 수 있도록 해준다
4. 피드백이나 도움이 필요할 때 혹은 자신의 Branch가 merge할 준비가 되었다면, PR을 생성하여 공유한다.
pull request는 코드 리뷰를 도와주는 시스템
이것을 이용해 자신의 코드를 공유하고, 리뷰받자
merge 준비가 완료되었다면 master 브랜치로 반영을 요구하자
5. PR 리뷰 후에는 다른 사람의 동의를 얻고 Master에 Merge한다.
곧장 product로 반영이될 기능이므로, 이해관계가 연결된 사람들과 충분한 논의 이후 반영하도록 한다
물론 CI도 통과해야한다!
6. Master Branch로 Merge나 Push가 이루어지면 즉시 배포해야한다.
GitHub-flow의 핵심
master로 merge가 일어나면 자동으로 배포가 되도록 설정해놓는다
마지막으로 GitLab-Flow란 GitLab에서 Git-Flow를 간소화하여 만든 브랜칭 전략이다.
또한 Github-flow는 너무나도 간단하여 배포, 환경 구성, 릴리즈, 통합에 대한 이슈를 남겨둔 것이 많았다.
그것을 보완하기 위해 GitLab에서 관련 내용들을 추가적인 가이드를 제공하여 전략을 만들었다.
아래는 GitLab-Flow의 특징이다.
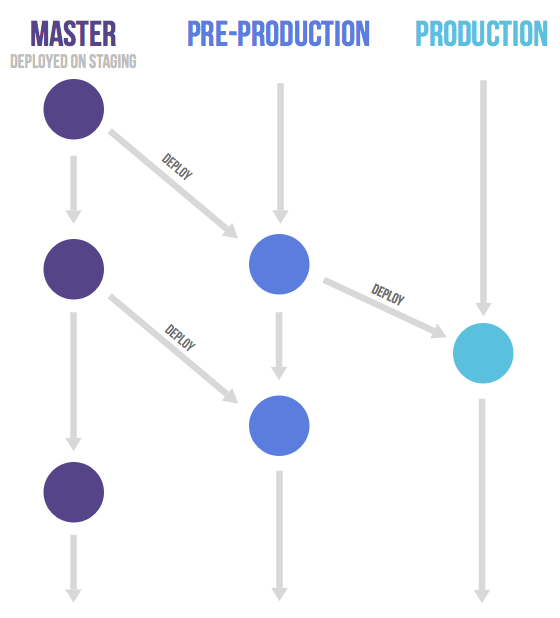
Production branch with GitLab flow
Github-Flow에서는 매번 Merge후에 배포를 하라고 하지만 iOS앱 등 배포 시기를 맞추지 못하는 서비스 등 이 특징을 매번 적용하기 힘든 경우가 있다.
이러한 경우들을 해결하기 위해 production브런치가 존재하여 커밋한 내용들을 일방적으로 배포하는 형태를 만들었다. GitHub에서 브런치 하나를 더 구성하여 사용하는 이것도 조금은 간단한 구성이다. 이렇게 구성하면 배포 자동화가 되어있지않은 구성에서 어떻게 배포를 진행할 것인가에 대한 내용을 담았다. 물론 이걸로 부족하여 다음의 것도 추가되었다.
Environment branches with GitLab flow
master와production사이에pre-production을 두어 개발한 내용을 곧장 반영하지 않고 시간을 두고 반영을 하는 것을 말한다. Staging을위한 공간인 pre-production에 MR을 Master에서 보낸다. 이와 같은 형식은 downstream flow의 방식을 취하게 되며 hotfix발생시 master에서 feature 브랜치를 만들어 수정 후 Master에 MR을 보낸다. feature 브랜치를 바로 삭제하지 않고 Master에서의 자동 테스트를 통과를 확인하고 삭제한다.
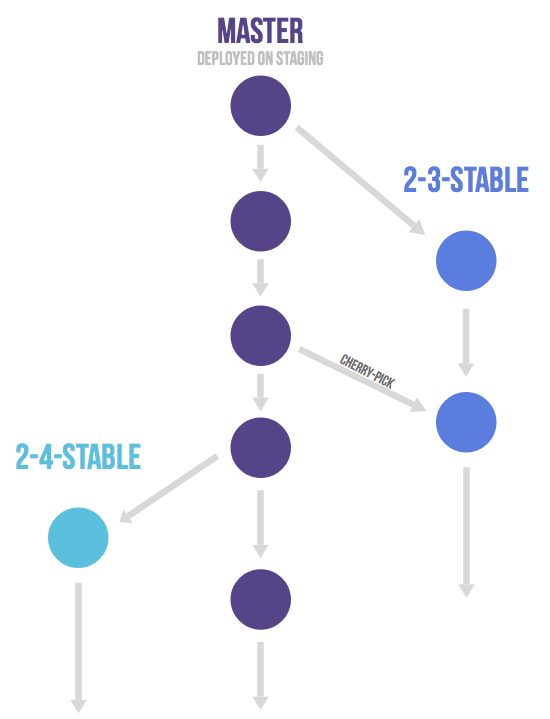
Release branches with GitLab flow
release한 브런치를 두고서 보안상 문제가 발생한 것이나 백 포트를 위해서 작업을 할 경우, cherry-pick을 이용해서 작업을 진행할 수 도 있다.(2-3 stable이나 2-4 stable등의 브랜치를 만들어서 작업) 아니면 해당 릴리즈에서 발생하는 버그들을 묶어서 수정하는 방식으로 작업한다. 일반적으로 말하는 ‘upstream first’ 정책이다. 같은 버그를 수정하는 경우를 방지하기 위해 태그를 달아서 패치 버전을 관리해주는 것이 좋다.
Merge/pull requests with GitLab flow
Pull request를 사용하는 방법이다. GitHub Flow에서 하는 방법과 동일하다.(Github에서는 pull request이고 GitLab에서는 Merge request임)
보호되고 있는 Long-live branch는 maintainer만 merge할 수 있도록 해야한다. Merge후에는 feature 브랜치는 삭제해주도록 한다.
Issues with GitLab flow
Issue 트러커와 연결하여 사용하는 것을 말한다. 긴 시간 동안 작업을 할 경우, 이슈를 생성하여 작업을 진행하는 것으로 브랜치 이름에는 이슈번호를 적어 작업 중인 이슈가 어떤 것인지를 명확하게 해주는 것이 필요하다. 작업이 끝나거나 코드 공유가 필요한 시점이면 Merge/pull requsts를 보낸다.
이 글을 작성하면서 가장 많은 도움을 받았던 블로그이다. 특히 GitLab 관련해서 일어 번역을 해주셔서 편하게 공부할 수 있었다.. 또한 장단점 정리가 깔끔했다.
회사에서 공부를 하다가 NAT이라는 용어가 나와서 들어는 봤지만 헷갈리는 단어라 다시 공부를 하게 되었다.
NAT이란 위키에 따르면
네트워크 주소 변환(영어:network address translation, 줄여서NAT)은 컴퓨터 네트워킹에서 쓰이는 용어로서,IP패킷의TCP/UDP포트 숫자와 소스 및 목적지의IP 주소등을 재기록하면서라우터를 통해네트워크 트래픽을 주고 받는 기술을 말한다. 패킷에 변화가 생기기 때문에 IP나 TCP/UDP의체크섬(checksum)도 다시 계산되어 재기록해야 한다. NAT를 이용하는 이유는 대개사설 네트워크에 속한 여러 개의 호스트가 하나의 공인 IP 주소를 사용하여인터넷에 접속하기 위함이다. 많은 네트워크 관리자들이 NAT를 편리한 기법이라고 보고 널리 사용하고 있다. NAT가 호스트 간의 통신에 있어서 복잡성을 증가시킬 수 있으므로 네트워크 성능에 영향을 줄 수 있는 것은 당연하다.
라고 한다..
말이 좀 어렵게 되어 있지만 간단하게 생각하면 우리가 가정집에서 사용하는 공유기에서 사용하는 여러기기가 있다면 각 기기마다 사설 IP 주소를 만들어주는 것이다. 그리고 우리가 인터넷을 사용할때에는 이러한 개인 IP 주소들을 공인 IP주소로 변환하여 인터넷에 접속을 하게된다.
위의 이미지를 보면 아마 쉽게 이해가 될것이다..
우리가 NAT을 사용하는 이유에는 두가지 정도가 있다.
첫번째는 공인 IPv4주소를 절약하기 위해서이다.
인터넷상의 공인 IP주소는 유한할 수 밖에 없다. 현재 IPv4의 경우 2의32승의 갯수만을 사용할 수 있으니 이러한 문제를 해결하기 위해서 NAT을 사용해 하나의 공유기에서 여러기기를 연결시키고 이를 통해 공인 IP 주소의 낭비를 줄이는 것이다.
두번째는 보안의 목적이다.
공개된 인터넷망에 사설 내부 IP가 노출된다면 개인PC로의 직접적인 접속 등 보안 사고가 발생할 수 있다. 따라서 NAT과 함께 방화벽을 사용함으로써 외부로의 공격을 예방 혹은 방어할 수 있다.
NAT의 동작원리나 자세한 사항은 참고자료에 있으니 나중에 공부할때 활용하면 좋을 것 같다!
계속 틀리다가 맞추었다. N*N으로 배열을 선언해야하는데 그 생각을 못하고 그냥 N으로 선언한 것이 패착이였다.
실제 시험장에서는 항상 변수 선언을 할때 생각을 하면서 해야할거 같다..
풀이는 BFS로 연합의 개수를 세고 각 2차원 배열로 각 연합의 인구수를 계산해서 저장을 해놓고
마지막에 인구수를 나눈 값을 넣어주는 형식으로 구성했다.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <vector>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
int N, L, R, ans, cnt = 1;
int map[51][51];
int visit[51][51];
int people[2555][2];
int dx[4] = { 0, 1, 0, -1 };
int dy[4] = { 1, 0, -1, 0 };
queue<pair<int, int>> q;
void bfs(int x, int y) {
q.push({ x, y });
visit[x][y] = cnt;
people[cnt][1]++;
people[cnt][0] += map[x][y];
while (!q.empty()) {
int s = q.size();
for (int i = 0; i < s; i++) {
int a = q.front().first;
int b = q.front().second;
q.pop();
for (int j = 0; j < 4; j++) { //국경을 열 수 있는지 확인
int c = a + dx[j];
int d = b + dy[j];
if (c >= 0 && d >= 0 && c < N && d < N && visit[c][d] == 0
&& abs(map[a][b] - map[c][d]) >= L
&& abs(map[a][b] - map[c][d]) <= R) {
q.push({ c, d });
visit[c][d] = cnt;
people[cnt][0] += map[c][d];
people[cnt][1]++;
}
}
}
}
return;
}
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
cin >> N >> L >> R;
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
cin >> map[i][j];
}
}
while (1) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
if (visit[i][j] == 0) {
bfs(i, j);
cnt++; //연합 갯수 증가
}
}
}
for (int i = 0; i < N; i++) { //연합 안의 사람들 재분배
for (int j = 0; j < N; j++) {
if (visit[i][j] > 0) {
map[i][j] = people[visit[i][j]][0] / people[visit[i][j]][1];
}
}
}
if (cnt > N * N) { //연합의 갯수가 N*N이면 중단
break;
}
ans++;
cnt = 1;
memset(people, 0, sizeof(people)); //배열 초기화
memset(visit, 0, sizeof(visit));
}
cout << ans;
return 0;
}